De nombreuses applications contiennent des informations ou des données spécifiques à l’utilisateur qui sont censées être accessibles par un certain groupe d’utilisateurs et non par d’autres. Ces types d’exigences s’accompagnent d’une demande de gestion d’accès détaillée. Que ce soit pour des raisons de sécurité ou de confidentialité, la gestion des données sensibles est un enjeu important pour toute application. Grand ou petit, personne ne veut être du mauvais côté d’un scandale de violation de données. Alors, plongeons dans ce que signifie gérer des informations sensibles ou confidentielles dans nos applications.
Prenez ça au sérieux
Que vous demandiez l’accès sur Twitter, une banque ou votre bibliothèque locale, vous identifier est une première étape cruciale. Tout type de porte vous avez besoin d’un moyen fiable pour vérifier si une demande d’accès est légitime.
« L’usurpation d’identité n’est pas une blague. »
—Dwight Schrute
Sur le Web, nous encapsulons le processus d’identification d’un utilisateur et lui accordons l’accès en tant que Autorisationqui représente deux actions liées mais distinctes :
- Authentification: action de confirmer l’identité d’un utilisateur.
- Autorisation: Accorder à un utilisateur authentifié l’accès à une ressource.
Il est possible d’avoir une authentification sans autorisation, mais pas l’inverse. La stratégie de mise en œuvre de l’autorisation au niveau de la gestion des données peut être vaguement appelée Sécurité au niveau de la ligne (RLS), mais RLS est en fait un peu plus que cela. Dans cet article, nous irons plus loin dans la gestion des données sensibles des utilisateurs et la définition des rôles d’accès à une base d’utilisateurs.
Sécurité au niveau de la ligne (RLS)
Une « ligne », dans ce cas, fait référence à une entrée dans une table de base de données. Par exemple, dans un éditions table, une ligne serait un seul articleRegarde ça json représentation:
{
"posts": [
{
"id": "article_23495044",
"title": "User Data Management",
"content": "<huge blob of text>",
"publishedAt": "2023-03-28",
"author": "author_2929292"
},
// ...
]
}
Pour comprendre le RLS, chaque object à l’intérieur éditions est une « ligne ».
Les données ci-dessus sont suffisantes pour créer un algorithme de filtrage afin d’appliquer efficacement la sécurité au niveau des lignes. Cependant, il est crucial pour l’évolutivité et la gestion des données que de tels relation est défini dans votre couche de données. De cette façon, tout service qui se connecte à votre base de données disposera de toutes les informations nécessaires pour mettre en œuvre sa propre logique de contrôle d’accès selon les besoins. Ainsi, pour l’exemple ci-dessus, le schème Pour lui éditions Le tableau ressemblerait à ceci :
{
"posts": {
"columns": [
{
"name": "id",
"type": "string"
},
// ... other primitive types
// establish relationship with "authors"
{
"name": "author",
"type": "link",
"link": "authors"
}
]
}
}
Dans l’exemple ci-dessus, nous définissons le type de chaque valeur dans notre éditions base de données et mise en place relation vers auteurs tableau. Ensuite, chaque publication recevra le id d’un auteur. Il s’agit d’une relation un-à-plusieurs : un l’auteur peut avoir beaucoup éditions
Bien sûr, il existe également des modèles pour définir des relations plusieurs-à-plusieurs. Prenez, par exemple, le backlog d’une équipe. Vous voudrez peut-être que seuls les membres d’une certaine équipe aient accès. Dans un tel cas, vous pouvez soit créer une liste d’utilisateurs ayant accès à une ressource spécifique (et donc être très précis à ce sujet), soit définir une table pour équipeet reliant ainsi un équipe au multitâche, et un équipe à plusieurs utilisateurs : ce modèle est appelé table syndicale et c’est super de définir accès délimité à l’intérieur de votre couche de données.
On comprend maintenant ce que autorisation c’est et semble dans certains cas. Cela devrait suffire à concevoir un modèle mental pour définir l’accès à nos données. Nous comprenons que pour utiliser efficacement l’accès granulaire à nos données, notre application doit être consciente de qui l’utilisateur utilise cette instance particulière de l’application (c’est-à-dire qui est derrière la souris).
Authentification
Le moment est venu de mettre en place un système fiable et rentable. authentification. Rentable car il est contre-productif de ré-authentifier l’utilisateur à chaque requête. Et cela augmente le facteur de risque d’attaques, alors réduisons au minimum les demandes d’authentification. La façon dont notre application stocke les informations d’identification des utilisateurs pour les réutiliser dans un cycle de vie défini s’appelle session.
Il existe plusieurs façons d’authentifier les utilisateurs et de gérer les sessions. Je vous invite à revoir l’article d’Eric Burel sur « Authentification de site Web : une analogie bancaire ». C’est une explication excellente et complète du fonctionnement de l’authentification.
À l’heure actuelle, supposons que nous ayons fait preuve de diligence raisonnable : le nom d’utilisateur et le mot de passe sont stockés en toute sécurité, un fournisseur d’authentification peut vérifier de manière fiable l’identité de notre utilisateur et il renvoie un sessionqui est un objet qui porte un userId correspondant à la ligne de notre utilisateur dans la base de données.
joindre les points
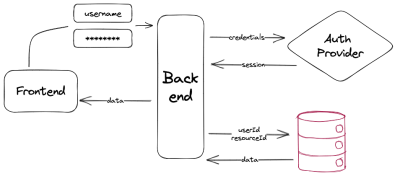
Alors maintenant que nous avons établi ce que cela signifie et les exigences que chaque pièce mobile apporte pour le faire fonctionner, notre objectif est le suivant :
- Authentification
Le fournisseur effectue l’authentification de l’utilisateur, la bibliothèque crée unsessionet l’application le reçoit comme unpayloadde la demande d’autorisation. - demande de ressource
L’utilisateur authentifié fait la demande avecresourceId; l’application prenduserIddesession. - autorisation d’accès
Filtre toutes les ressources du tableau uniquement pour celles détenues paruserIdet renvoie (s’il existe) celui qui aresourceId.
Avec le modèle mental précédent défini, il est possible de faire n’importe quel type d’implémentation et de concevoir correctement vos requêtes. Par exemple, dans notre premier schéma défini (messages et auteurs), nous pouvons utiliser des filtres dans notre service de recherche pour donner accès uniquement aux résultats qu’un utilisateur devrait avoir :
async function getPostsByAuthor(authorId: string) {
return sdk.db.posts
.filter({
author: authorId
})
.getPaginated()
}
Cet extrait artificiel est juste pour illustrer une implémentation RLS de base. Peut-être comme matière à réflexion pour que vous puissiez en tirer parti.
conclusion
Espérons que ces concepts ont fourni une plus grande clarté dans la définition de la gestion de l’accès aux données privées et/ou confidentielles. Il est important de noter qu’il existe des problèmes de sécurité avant et autour du stockage de ce type de données qui sortaient du cadre de cet article. En règle générale: stockez aussi peu que nécessaire et ne fournissez que la quantité nécessaire d’accès aux données. Moins les données sensibles transitent par le réseau ou sont stockées par votre application, moins votre application est susceptible d’être la cible ou la victime d’attaques ou de fuites.
Faites-moi part de vos questions ou commentaires dans la section des commentaires ou sur Twitter.
(Ouais)
